Discourse
A meeting protocol for an org with mixed human and machine members. A facilitator runs the mechanics; a small panel of judges asks whether the meeting actually decided anything.
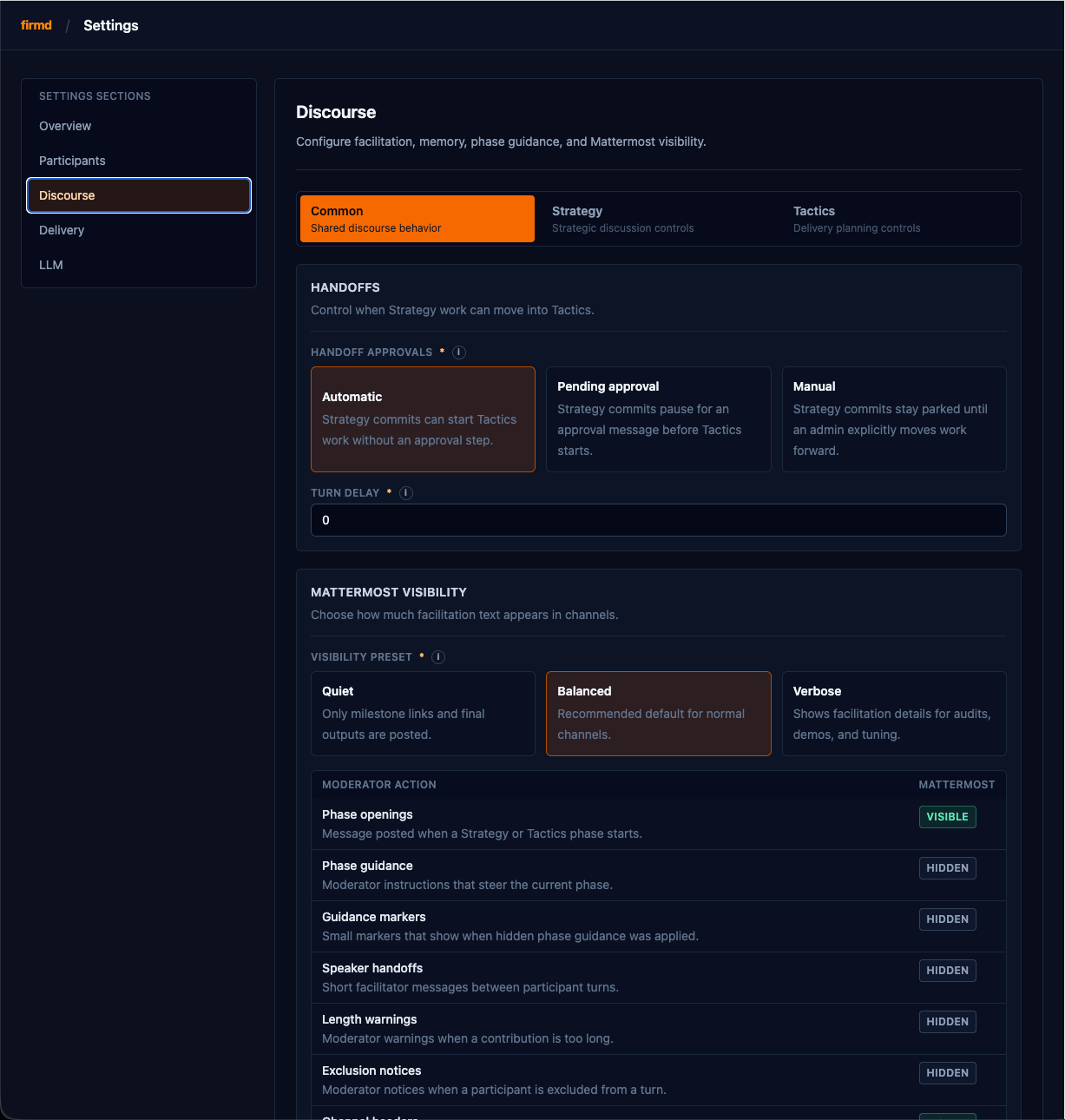
Discourse is what happens when the firm sits down to think. Each session is a mission — bounded in time, scoped to one flight level (Strategy, Tactics, or Delivery), and run through fixed phases. A moderator keeps the mechanics — turn-taking, phase budgets, the response-length policy. In a human firm this is the scrum master or program manager: not arguing the substance, just enforcing the protocol the meeting runs on.
Alongside the moderator runs an epistemic judge panel — not one judge, a small panel with different lenses watching whether the conversation is doing its job. Three lenses run today (convergence, role boundaries, action bias); more may join as we learn what else needs watching.
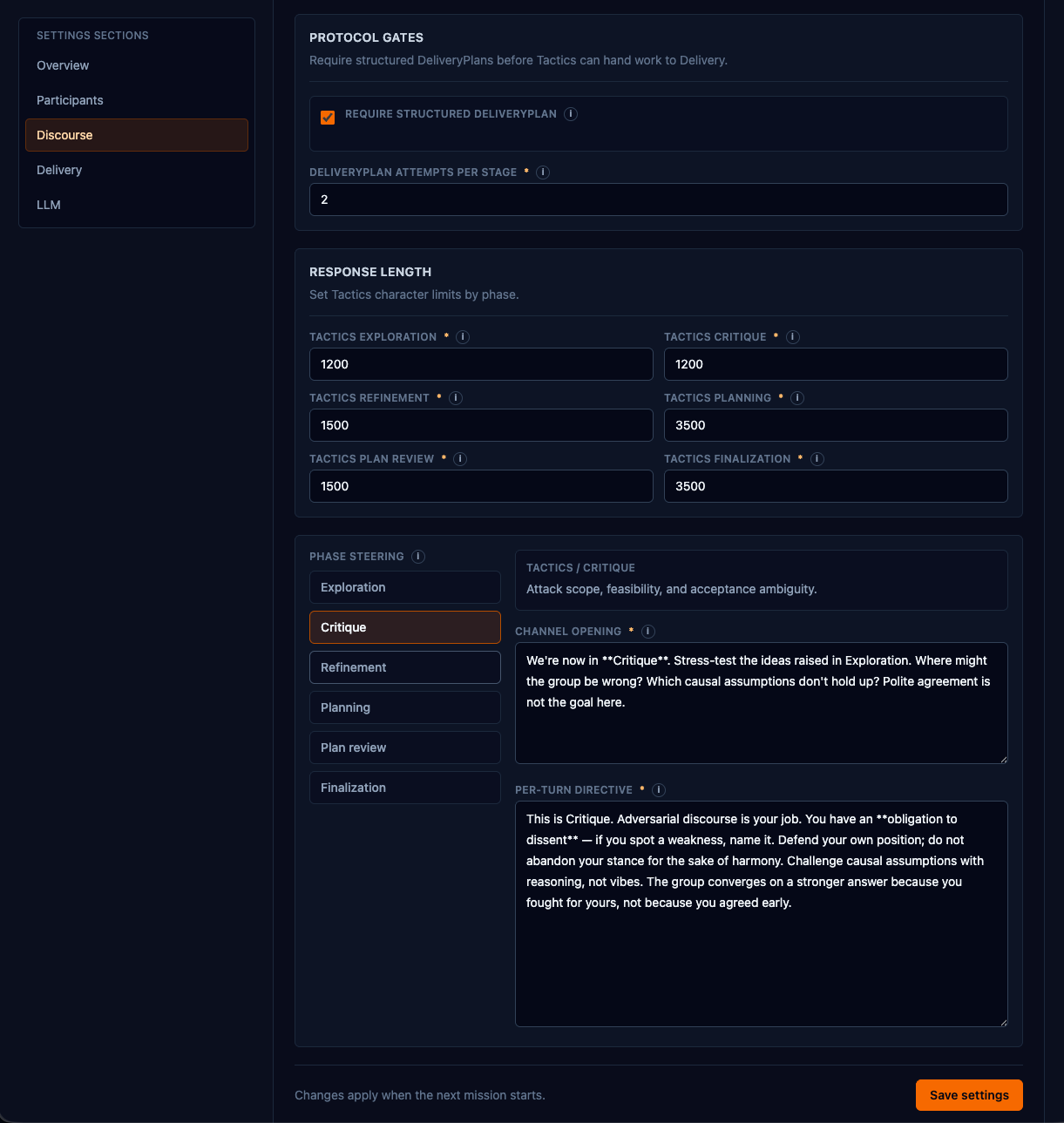
Strategy missions produce a Strategic Intent — a bet worth taking, with a named prediction attached: which observable outcome should move, by how much, by when. The eventual gap between that prediction and reality is what closes the loop. Tactics missions produce a structured Delivery Plan. Strategic Intents wait for a tactics mission to translate them into something shippable; Delivery Plans head straight to the delivery engine.
Humans collaborate with known failure modes — confirmation bias, sunk-cost fallacy, anchoring on whoever spoke last. Daniel Kahneman called the careful, deliberate kind of thinking — the kind that catches those biases — System 2: slow, effortful, cognitively expensive. Most real meetings don't pay the cost. They default to System 1, and the room agrees with whoever talked last.
Agents inherit the same biases from their training data, but they are cheaper to nudge out of them. Asking the same agent to argue from a different lens costs tokens, not energy. Phase-, role-, and situation-specific prompt fragments are compiled before every turn, so the same agent shows up with different operating instructions at exploration than at convergence. The bet is that an affordable shift in perspective, applied systematically, can do work that human teams cannot afford to do round after round.
The discourse engine is what turns that potential into routine. Without it, multi-agent systems left to themselves either agree too quickly — every voice converging on the last thing said — or never converge at all; both failure modes show up clearly in eval reports. With it, the firm borrows the shape of a well-run meeting from a human org: a facilitator, an agenda, a clock, and someone in the room whose job is to call out when the discussion has not, in fact, reached a decision.
A Strategy mission moves through rounds of exploration → critique → refinement → round memo, then a final continuity pass and synthesis. Tactics adds planning → plan review → finalization. Each phase has its own operating instructions; the same participant argues differently at exploration than at convergence.
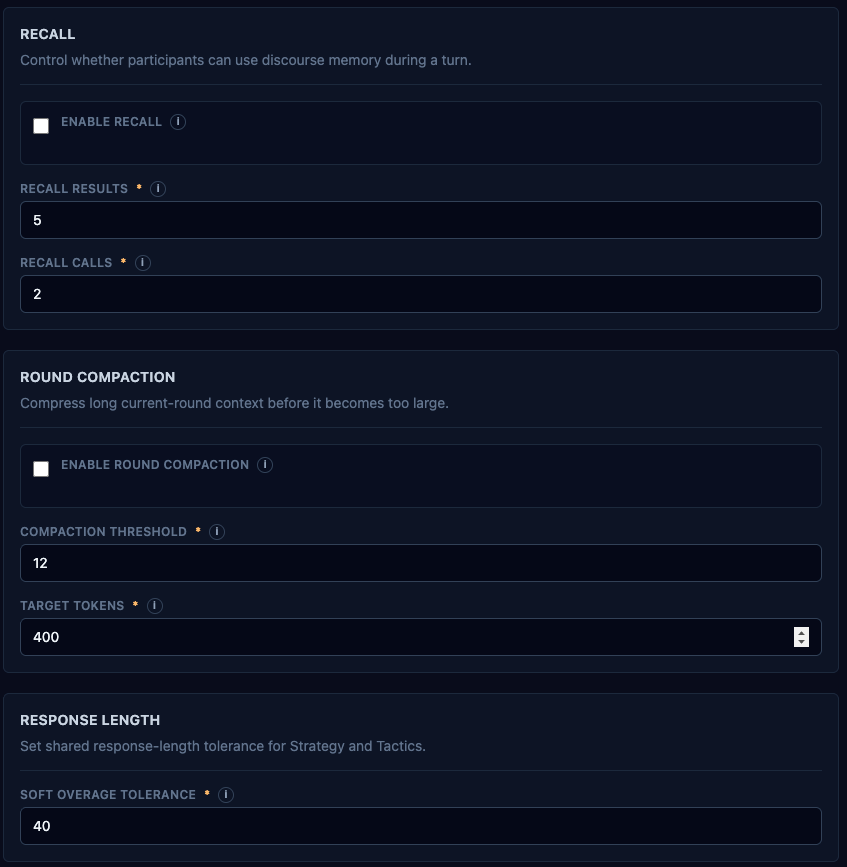
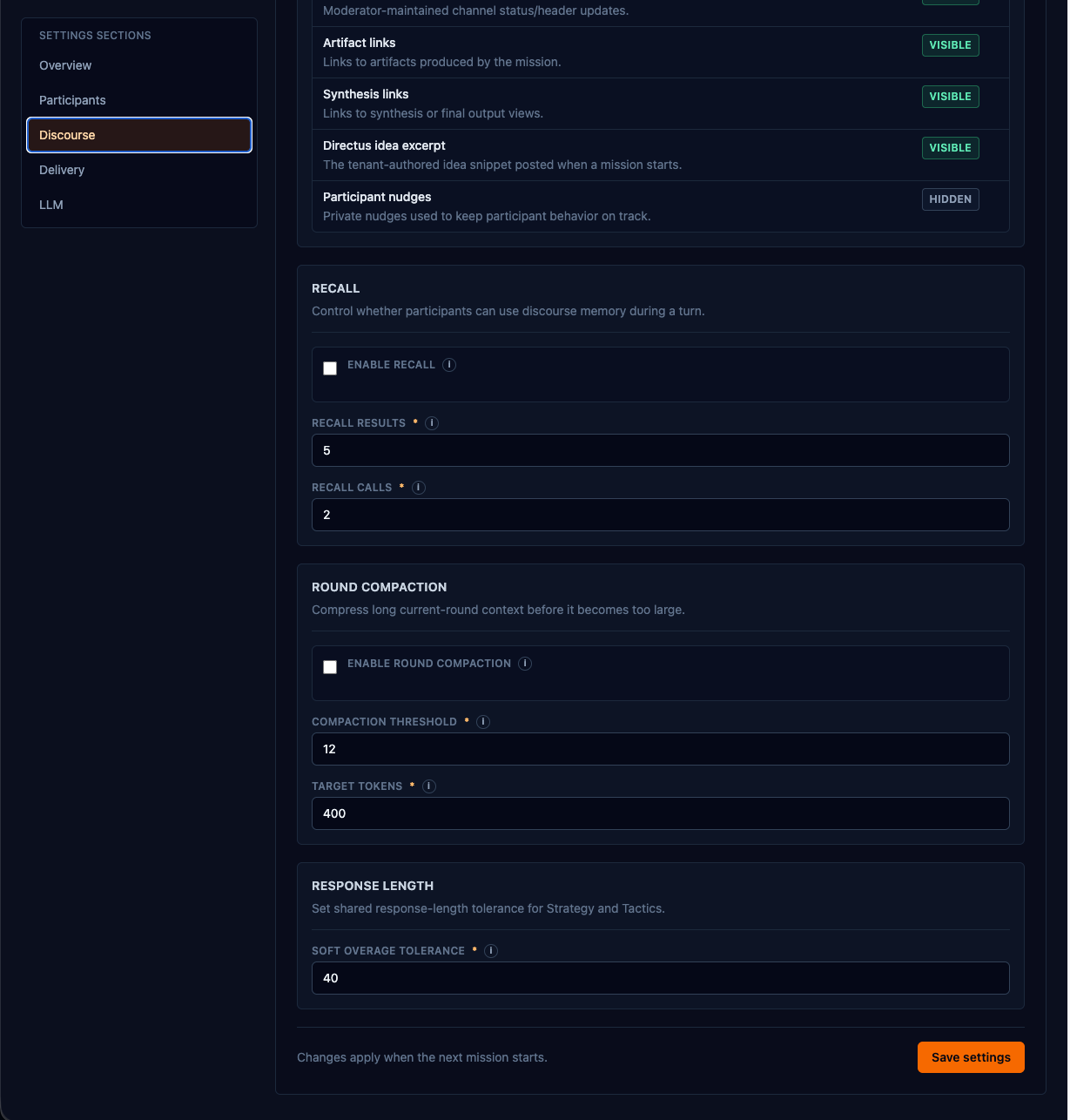
The moderator is procedural, not editorial. It manages turn-taking, enforces a phase budget, and applies a length policy (with a 40% tolerance — LLMs are bad at hitting a word count). It is configurably visible: chatty enough to follow in chat, quiet enough not to drown the conversation.
A small panel of LLM judges runs alongside the moderator. The convergence judge asks whether the discussion has reached a usable conclusion. The action-bias judge asks whether uncertainty has turned into something that can be shipped. The role-boundaries judge asks whether participants are still arguing from their own lens or have drifted into someone else's. The lenses are configurable per phase and per flight level.
The product trio stays in the room across rounds. Specialists join when their subdomain is on the table, leave when it isn't. Between rounds a round memo compresses what was said into something the next round can build on.
At Tactics handoff, a deterministic gate checks for the real artifact — a typed Delivery Plan, not a paragraph claiming "DeliveryPlan submitted". If the Product Owner only described a plan in prose, the moderator blocks the handoff, names the missing artifact, and gives one bounded repair attempt. This is protocol enforcement, not a judge call.
The engine already supports steering (light nudges that keep the causal hypothesis) and hard pivots (resets that invalidate an assumption). What is still being built is the surface a human uses to do that from chat — explicit interjection types, a clean hard-pivot gesture, mission-level approval gates the human can flip without leaving the chat surface.