Evaluation
A firm of agents that does not measure itself drifts into theatre. Evaluation is the discipline that keeps the rest of firmd honest — the place every recent rebalance and every protocol gate came from.
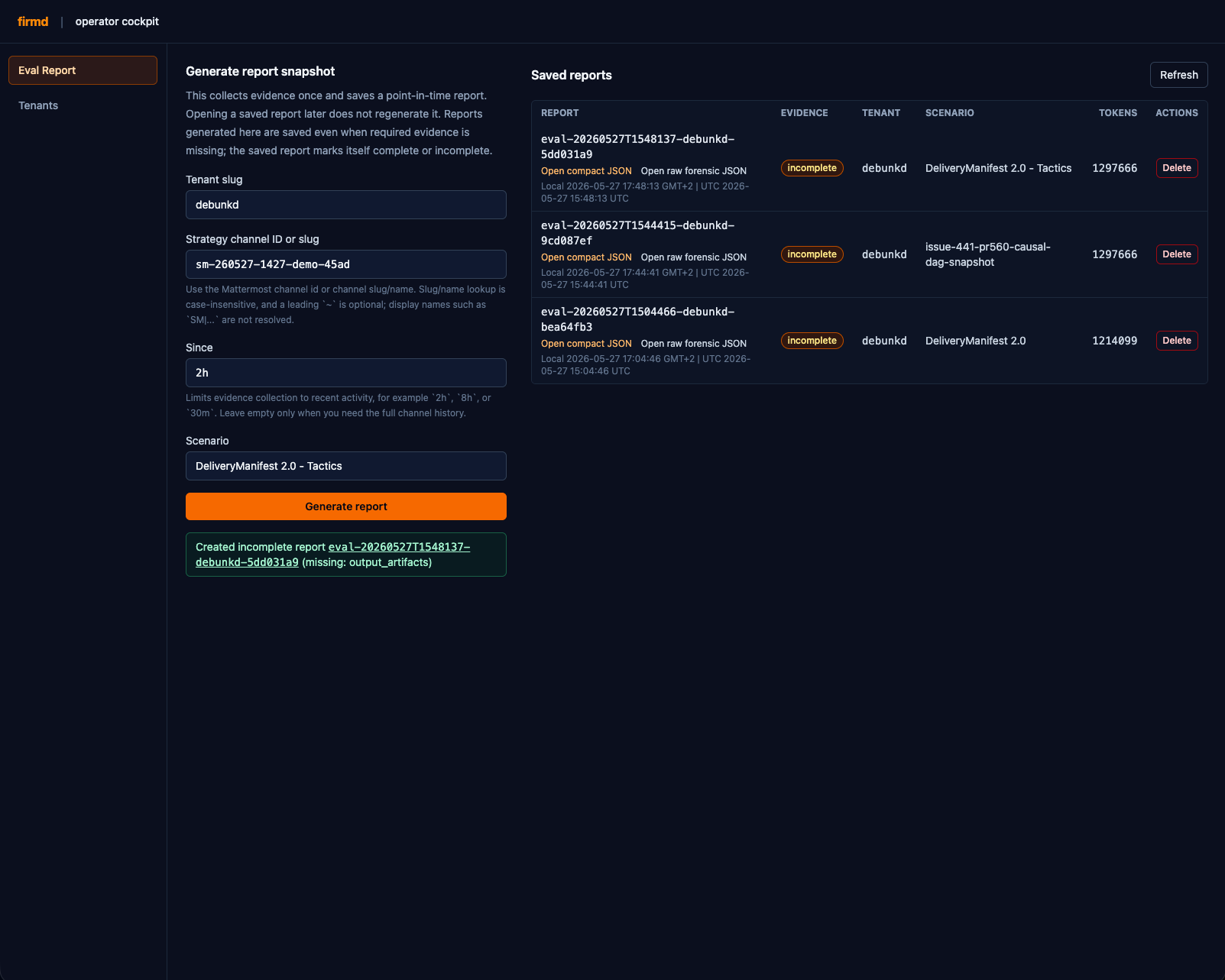
Evaluation is a per-mission report (generated via API), after the fact, that opens up what the firm did and asks questions: did the system run, did it deliberate well, did it produce something useful, is it learning across missions and how much does it costs (token consumption)?
The pilot tenant is debunkd.social — a
real product brief that lets us exercise Strategy,
Tactics, and Delivery end to end without inventing a
synthetic one.
Most runs either local Ollama `qwen3.5:27b` or using
Ollama with quen3.5:397b-cloud; frontier models are
reserved for interpretation of eval reports.
Operational reliability (latency, retries, token spend), deliberation quality (challenge density, convergence, signal loss in compaction), outcome quality (clarity, completeness, execution-readiness of artifacts), and longitudinal learning (whether repeated missions on the same tenant get better).
Reports are built from OpenTelemetry signals the firm already emits — judge decisions, moderation events, collaboration edges, token usage. The report is structured enough to compare two runs side by side without re-reading transcripts.
An eval finding does not stay in the report. Recent
examples: prompt-economy work to drop repeated input
tokens against frontier models; a deterministic protocol
gate that blocks Tactics handoff when the Product Owner
only described a plan in prose; cleaner separation
between the judge panel and the moderator. And many
more...
The deepest lesson so far: when the agents misbehave, the fix is rarely "a smarter judge" — it is usually a deterministic check the moderator should have done. The system has steadily moved load from epistemic judges toward procedural gates. Cheaper, more predictable, easier to debug.
This is not a benchmark. firmd is not trying to win a leaderboard. The pilot is one product, the eval set is small by design, and the failure modes that turn up are interesting precisely because we cannot anticipate them. Some of what we ship will work. Some of it will document, in retrospect, a specific way that an agentic firm gets things wrong. Both are useful.